elephant.asset.ASSET¶
-
class
elephant.asset.ASSET(spiketrains_i, spiketrains_j=None, bin_size=array(3.0) * ms, t_start_i=None, t_start_j=None, t_stop_i=None, t_stop_j=None, verbose=True)[source]¶ Analysis of Sequences of Synchronous EvenTs class.
Parameters: - spiketrains_i, spiketrains_jlist of neo.SpikeTrain
Input spike trains for the first and second time dimensions, respectively, to compute the p-values from. If spiketrains_y is None, it’s set to spiketrains.
- bin_sizepq.Quantity, optional
The width of the time bins used to compute the probability matrix.
- t_start_i, t_start_jpq.Quantity, optional
The start time of the binning for the first and second axes, respectively. If None, the attribute t_start of the spike trains is used (if the same for all spike trains). Default: None.
- t_stop_i, t_stop_jpq.Quantity, optional
The stop time of the binning for the first and second axes, respectively. If None, the attribute t_stop of the spike trains is used (if the same for all spike trains). Default: None.
- verbosebool, optional
If True, print messages and show progress bar. Default: True.
Raises: - ValueError
- If the t_start & t_stop times are not (one of):
perfectly aligned;
fully disjoint.
Methods
intersection_matrix([normalization])Generates the intersection matrix from a list of spike trains. probability_matrix_montecarlo(n_surrogates)Given a list of parallel spike trains, estimate the cumulative probability of each entry in their intersection matrix by a Monte Carlo approach using surrogate data. probability_matrix_analytical([imat, …])Given a list of spike trains, approximates the cumulative probability of each entry in their intersection matrix. joint_probability_matrix(pmat, filter_shape, …)Map a probability matrix pmat to a joint probability matrix jmat, where jmat[i, j] is the joint p-value of the largest neighbors of pmat[i, j]. mask_matrices(matrices, thresholds)Given a list of matrices and a list of thresholds, return a boolean matrix B (“mask”) such that B[i,j] is True if each input matrix in the list strictly exceeds the corresponding threshold at that position. cluster_matrix_entries(mask_matrix, …)Given a matrix mask_matrix, replaces its positive elements with integers representing different cluster IDs. extract_synchronous_events(cmat[, ids])Given a list of spike trains, a bin size, and a clustered intersection matrix obtained from those spike trains via ASSET analysis, extracts the sequences of synchronous events (SSEs) corresponding to clustered elements in the cluster matrix. Attributes
x_edgesA Quantity array of n+1 edges of the bins used for the horizontal axis of the intersection matrix, where n is the number of bins that time was discretized in. y_edgesA Quantity array of n+1 edges of the bins used for the vertical axis of the intersection matrix, where n is the number of bins that time was discretized in. -
static
cluster_matrix_entries(mask_matrix, max_distance, min_neighbors, stretch)[source]¶ Given a matrix mask_matrix, replaces its positive elements with integers representing different cluster IDs. Each cluster comprises close-by elements.
In ASSET analysis, mask_matrix is a thresholded (“masked”) version of the intersection matrix imat, whose values are those of imat only if considered statistically significant, and zero otherwise.
A cluster is built by pooling elements according to their distance, via the DBSCAN algorithm (see sklearn.cluster.DBSCAN class). Elements form a neighbourhood if at least one of them has a distance not larger than max_distance from the others, and if they are at least min_neighbors. Overlapping neighborhoods form a cluster:
- Clusters are assigned integers from 1 to the total number k of clusters;
- Unclustered (“isolated”) positive elements of mask_matrix are assigned value -1;
- Non-positive elements are assigned the value 0.
The distance between the positions of two positive elements in mask_matrix is given by a Euclidean metric which is stretched if the two positions are not aligned along the 45 degree direction (the main diagonal direction), as more, with maximal stretching along the anti-diagonal. Specifically, the Euclidean distance between positions (i1, j1) and (i2, j2) is stretched by a factor
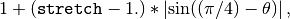
where
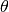 is the angle between the pixels and the 45 degree
direction. The stretching factor thus varies between 1 and stretch.
is the angle between the pixels and the 45 degree
direction. The stretching factor thus varies between 1 and stretch.Parameters: - mask_matrixnp.ndarray
The boolean matrix, whose elements with positive values are to be clustered. The output of
ASSET.mask_matrices().- max_distancefloat
The maximum distance between two elements in mask_matrix to be a part of the same neighbourhood in the DBSCAN algorithm.
- min_neighborsint
The minimum number of elements to form a neighbourhood.
- stretchfloat
The stretching factor of the euclidean metric for elements aligned along the 135 degree direction (anti-diagonal). The actual stretching increases from 1 to stretch as the direction of the two elements moves from the 45 to the 135 degree direction. stretch must be greater than 1.
Returns: - cluster_matnp.ndarray
A matrix with the same shape of mask_matrix, each of whose elements is either:
- a positive integer (cluster ID) if the element is part of a cluster;
- 0 if the corresponding element in mask_matrix is non-positive;
- -1 if the element does not belong to any cluster.
See also
sklearn.cluster.DBSCAN
-
extract_synchronous_events(cmat, ids=None)[source]¶ Given a list of spike trains, a bin size, and a clustered intersection matrix obtained from those spike trains via ASSET analysis, extracts the sequences of synchronous events (SSEs) corresponding to clustered elements in the cluster matrix.
Parameters: - cmat: (n,n) np.ndarray
The cluster matrix, the output of
ASSET.cluster_matrix_entries().- idslist, optional
A list of spike train IDs. If provided, ids[i] is the identity of spiketrains[i]. If None, the IDs 0,1,…,n-1 are used. Default: None.
Returns: - sse_dictdict
A dictionary D of SSEs, where each SSE is a sub-dictionary Dk, k=1,…,K, where K is the max positive integer in cmat (i.e., the total number of clusters in cmat):
D = {1: D1, 2: D2, …, K: DK}
Each sub-dictionary Dk represents the k-th diagonal structure (i.e., the k-th cluster) in cmat, and is of the form
Dk = {(i1, j1): S1, (i2, j2): S2, …, (iL, jL): SL}.
The keys (i, j) represent the positions (time bin IDs) of all elements in cmat that compose the SSE (i.e., that take value l and therefore belong to the same cluster), and the values Sk are sets of neuron IDs representing a repeated synchronous event (i.e., spiking at time bins i and j).
-
intersection_matrix(normalization=None)[source]¶ Generates the intersection matrix from a list of spike trains.
Given a list of neo.SpikeTrain, consider two binned versions of them differing for the starting and ending times of the binning: t_start_x, t_stop_x, t_start_y and t_stop_y respectively (the time intervals can be either identical or completely disjoint). Then calculate the intersection matrix M of the two binned data, where M[i,j] is the overlap of bin i in the first binned data and bin j in the second binned data (i.e., the number of spike trains spiking at both bin i and bin j).
The matrix entries can be normalized to values between 0 and 1 via different normalizations (see “Parameters” section).
Parameters: - normalization{‘intersection’, ‘mean’, ‘union’} or None, optional
The normalization type to be applied to each entry M[i,j] of the intersection matrix M. Given the sets s_i and s_j of neuron IDs in the bins i and j respectively, the normalization coefficient can be:
- None: no normalisation (row counts)
- ‘intersection’: len(intersection(s_i, s_j))
- ‘mean’: sqrt(len(s_1) * len(s_2))
- ‘union’: len(union(s_i, s_j))
Default: None.
Returns: - imat(n,n) np.ndarray
The floating point intersection matrix of a list of spike trains. It has the shape (n, n), where n is the number of bins that time was discretized in.
-
joint_probability_matrix(pmat, filter_shape, n_largest, min_p_value=1e-05)[source]¶ Map a probability matrix pmat to a joint probability matrix jmat, where jmat[i, j] is the joint p-value of the largest neighbors of pmat[i, j].
The values of pmat are assumed to be uniformly distributed in the range [0, 1]. Centered a rectangular kernel of shape filter_shape=(l, w) around each entry pmat[i, j], aligned along the diagonal where pmat[i, j] lies into, extracts the n_largest values falling within the kernel and computes their joint p-value jmat[i, j].
Parameters: - pmatnp.ndarray
A square matrix, the output of
ASSET.probability_matrix_montecarlo()orASSET.probability_matrix_analytical(), of cumulative probability values between 0 and 1. The values are assumed to be uniformly distributed in the said range.- filter_shapetuple of int
A pair of integers representing the kernel shape (l, w).
- n_largestint
The number of the largest neighbors to collect for each entry in jmat.
- min_p_valuefloat, optional
The minimum p-value in range [0, 1) for individual entries in pmat. Each pmat[i, j] is set to min(pmat[i, j], 1-p_value_min) to avoid that a single highly significant value in pmat (extreme case: pmat[i, j] = 1) yields joint significance of itself and its neighbors. Default: 1e-5.
Returns: - jmatnp.ndarray
The joint probability matrix associated to pmat.
-
static
mask_matrices(matrices, thresholds)[source]¶ Given a list of matrices and a list of thresholds, return a boolean matrix B (“mask”) such that B[i,j] is True if each input matrix in the list strictly exceeds the corresponding threshold at that position. If multiple matrices are passed along with only one threshold the same threshold is applied to all matrices.
Parameters: - matriceslist of np.ndarray
The matrices which are compared to the respective thresholds to build the mask. All matrices must have the same shape. Typically, it is a list [pmat, jmat], i.e., the (cumulative) probability and joint probability matrices.
- thresholdsfloat or list of float
The significance thresholds for each matrix in matrices.
Returns: - masknp.ndarray
Boolean mask matrix with the shape of the input matrices.
Raises: - ValueError
If matrices or thresholds is an empty list.
If matrices and thresholds have different lengths.
See also
ASSET.probability_matrix_montecarlo- for pmat generation
ASSET.probability_matrix_analytical- for pmat generation
ASSET.joint_probability_matrix- for jmat generation
-
probability_matrix_analytical(imat=None, firing_rates_x='estimate', firing_rates_y='estimate', kernel_width=array(100.0) * ms)[source]¶ Given a list of spike trains, approximates the cumulative probability of each entry in their intersection matrix.
The approximation is analytical and works under the assumptions that the input spike trains are independent and Poisson. It works as follows:
- Bin each spike train at the specified bin_size: this yields a binary array of 1s (spike in bin) and 0s (no spike in bin; clipping used);
- If required, estimate the rate profile of each spike train by convolving the binned array with a boxcar kernel of user-defined length;
- For each neuron k and each pair of bins i and j, compute
the probability
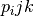 that neuron k fired in both bins
i and j.
that neuron k fired in both bins
i and j. - Approximate the probability distribution of the intersection
value at (i, j) by a Poisson distribution with mean parameter
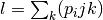 ,
justified by Le Cam’s approximation of a sum of independent
Bernouilli random variables with a Poisson distribution.
,
justified by Le Cam’s approximation of a sum of independent
Bernouilli random variables with a Poisson distribution.
Parameters: - imat(n,n) np.ndarray or None, optional
The intersection matrix of a list of spike trains. It has the shape (n, n), where n is the number of bins that time was discretized in. If None, the output of
ASSET.intersection_matrix()is used. Default: None- firing_rates_x, firing_rates_ylist of neo.AnalogSignal or ‘estimate’
If a list, firing_rates[i] is the firing rate of the spike train spiketrains[i]. If ‘estimate’, firing rates are estimated by simple boxcar kernel convolution, with the specified kernel_width. Default: ‘estimate’.
- kernel_widthpq.Quantity, optional
The total width of the kernel used to estimate the rate profiles when firing_rates is ‘estimate’. Default: 100 * pq.ms.
Returns: - pmatnp.ndarray
The cumulative probability matrix. pmat[i, j] represents the estimated probability of having an overlap between bins i and j STRICTLY LOWER than the observed overlap, under the null hypothesis of independence of the input spike trains.
-
probability_matrix_montecarlo(n_surrogates, imat=None, surrogate_method='dither_spikes', surrogate_dt=None)[source]¶ Given a list of parallel spike trains, estimate the cumulative probability of each entry in their intersection matrix by a Monte Carlo approach using surrogate data.
Contrarily to the analytical version (see
ASSET.probability_matrix_analytical()) the Monte Carlo one does not incorporate the assumptions of Poissonianity in the null hypothesis.The method produces surrogate spike trains (using one of several methods at disposal, see “Parameters” section) and calculates their intersection matrix M. For each entry (i, j), the intersection CDF P[i, j] is then given by:
P[i, j] = #(spike_train_surrogates such that M[i, j] < I[i, j]) / #(spike_train_surrogates)
If P[i, j] is large (close to 1), I[i, j] is statistically significant: the probability to observe an overlap equal to or larger than I[i, j] under the null hypothesis is 1 - P[i, j], very small.
Parameters: - n_surrogatesint
The number of spike train surrogates to generate for the bootstrap procedure.
- imat(n,n) np.ndarray or None, optional
The floating point intersection matrix of a list of spike trains. It has the shape (n, n), where n is the number of bins that time was discretized in. If None, the output of
ASSET.intersection_matrix()is used. Default: None- surrogate_method{‘dither_spike_train’, ‘dither_spikes’,
‘jitter_spikes’, ‘randomise_spikes’, ‘shuffle_isis’, ‘joint_isi_dithering’}, optional
The method to generate surrogate spike trains. Refer to the
spike_train_surrogates.surrogates()documentation for more information about each surrogate method. Note that some of these methods need surrogate_dt parameter, others ignore it. Default: ‘dither_spike_train’.- surrogate_dtpq.Quantity, optional
For surrogate methods shifting spike times randomly around their original time (‘dither_spike_train’, ‘dither_spikes’) or replacing them randomly within a certain window (‘jitter_spikes’), surrogate_dt represents the size of that shift (window). For other methods, surrogate_dt is ignored. If None, it’s set to self.bin_size * 5. Default: None.
Returns: - pmatnp.ndarray
The cumulative probability matrix. pmat[i, j] represents the estimated probability of having an overlap between bins i and j STRICTLY LOWER than the observed overlap, under the null hypothesis of independence of the input spike trains.
See also
ASSET.probability_matrix_analytical- analytical derivation of the matrix
Notes
We recommend playing with surrogate_dt parameter to see how it influences the result matrix. For this, refer to the ASSET tutorial.
-
property
x_edges¶ A Quantity array of n+1 edges of the bins used for the horizontal axis of the intersection matrix, where n is the number of bins that time was discretized in.
-
property
y_edges¶ A Quantity array of n+1 edges of the bins used for the vertical axis of the intersection matrix, where n is the number of bins that time was discretized in.