elephant.spike_train_dissimilarity.van_rossum_distance¶
-
elephant.spike_train_dissimilarity.van_rossum_distance(spiketrains, time_constant=array(1.0) * s, sort=True)[source]¶ Calculates the van Rossum distance.
It is defined as Euclidean distance of the spike trains convolved with a causal decaying exponential smoothing filter. A detailed description can be found in [1]_. This implementation is normalized to yield a distance of 1.0 for the distance between an empty spike train and a spike train with a single spike. Divide the result by sqrt(2.0) to get the normalization used in the cited paper.
Given
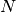 spike trains with
spike trains with 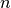 spikes on average the run-time
complexity of this function is
spikes on average the run-time
complexity of this function is 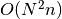 .
.Parameters: - spiketrainsSequence of
neo.core.SpikeTrainobjects of which the van Rossum distance will be calculated pairwise.
- time_constantQuantity scalar
Decay rate of the exponential function as time scalar. Controls for which time scale the metric will be sensitive. Denoted as
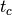 in [1]_. This parameter will be ignored if kernel is not None.
May also be
in [1]_. This parameter will be ignored if kernel is not None.
May also be scipy.infwhich will lead to only measuring differences in spike count. Default: 1.0 * pq.s- sortbool
Spike trains with sorted spike times might be needed for the calculation. You can set sort to False if you know that your spike trains are already sorted to decrease calculation time. Default: True
Returns: - np.ndarray
2-D Matrix containing the van Rossum distances for all pairs of spike trains.
References
- [1] Rossum, M. V. (2001). A novel spike distance. Neural computation,
- 13(4), 751-763.
Examples
>>> from elephant.spike_train_dissimilarity import van_rossum_distance >>> tau = 10.0 * pq.ms >>> st_a = SpikeTrain([10, 20, 30], units='ms', t_stop= 1000.0) >>> st_b = SpikeTrain([12, 24, 30], units='ms', t_stop= 1000.0) >>> vr = van_rossum_distance([st_a, st_b], tau)[0, 1]
- spiketrainsSequence of