The Unitary Events Analysis¶
The executed version of this tutorial is at https://elephant.readthedocs.io/en/latest/tutorials/unitary_event_analysis.html
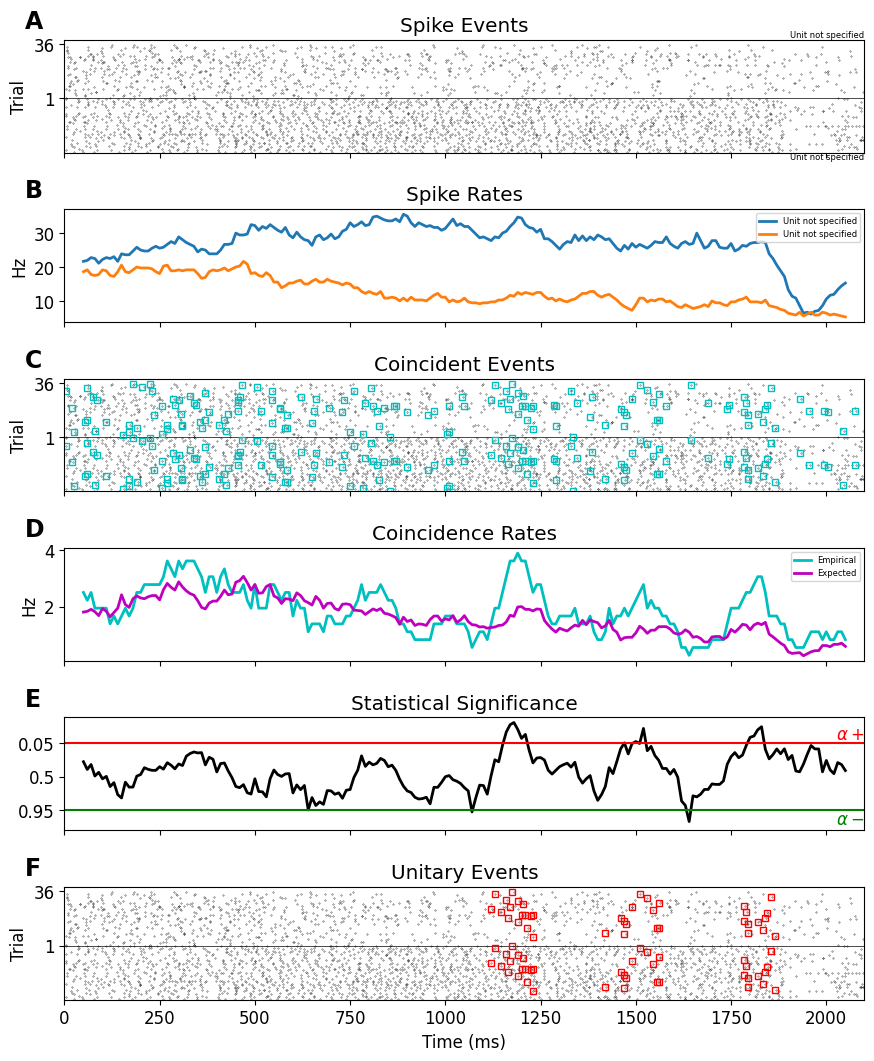
The Unitary Events (UE) analysis [1] tool allows us to reliably detect correlated spiking activity that is not explained by the firing rates of the neurons alone. It was designed to detect coordinated spiking activity that occurs significantly more often than predicted by the firing rates of the neurons. The method allows one to analyze correlations not only between pairs of neurons but also between multiple neurons, by considering the various spike patterns across the neurons. In addition, the method allows one to extract the dynamics of correlation between the neurons by perform-ing the analysis in a time-resolved manner. This enables us to relate the occurrence of spike synchrony to behavior.
The algorithm:
Align trials, decide on width of analysis window.
Decide on allowed coincidence width.
Perform a sliding window analysis. In each window:
Detect and count coincidences.
Calculate expected number of coincidences.
Evaluate significance of detected coincidences.
If significant, the window contains Unitary Events.
Explore behavioral relevance of UE epochs.
References:
Grün, S., Diesmann, M., Grammont, F., Riehle, A., & Aertsen, A. (1999). Detecting unitary events without discretization of time. Journal of neuroscience methods, 94(1), 67-79.
[1]:
import random
import matplotlib.pyplot as plt
import quantities as pq
import elephant.unitary_event_analysis as ue
from elephant.datasets import load_data
from viziphant.unitary_event_analysis import plot_ue
# Fix random seed to guarantee fixed output
random.seed(1224)
%matplotlib inline
/home/docs/checkouts/readthedocs.org/user_builds/elephant/conda/latest/lib/python3.12/site-packages/holoviews/util/parser.py:155: PyparsingDeprecationWarning: 'nestedExpr' deprecated - use 'nested_expr'
plot_options_short = pp.nestedExpr('[',
/home/docs/checkouts/readthedocs.org/user_builds/elephant/conda/latest/lib/python3.12/site-packages/holoviews/util/parser.py:158: PyparsingDeprecationWarning: 'setResultsName' deprecated - use 'set_results_name'
).setResultsName('plot_options')
/home/docs/checkouts/readthedocs.org/user_builds/elephant/conda/latest/lib/python3.12/site-packages/pyparsing/util.py:477: PyparsingDeprecationWarning: 'ignoreExpr' argument is deprecated, use 'ignore_expr'
return fn(*args, **kwargs)

 ⓘ
ⓘ
Load data and extract spiketrains¶
First, we load the data with the spiking activity of 2 neurons across 36 trials.
The spike trains are stored in a dataset saved with the NIX file format. The data in the NIX file is represented as a neo.Block containing 36 neo.Segments, one for each trial. The neo.Segment contains 2 neo.SpikeTrain objects, each corresponding to the activity of one neuron in the trial.
The NIX file will be automatically downloaded from https://datasets.python-elephant.org and the spiking activity data loaded into the variable spiketrains. This variable will store the trial data as a list of lists, where each of the 36 inner lists contains the neo.SpikeTrain objects with the activity of both neurons in a single trial.
For more information on neo.Block, neo.Segment, and neo.SpikeTrain refer to https://neo.readthedocs.io/en/stable/api_reference.html.
[2]:
spiketrains = load_data('unitary_events')
Downloading https://datasets.python-elephant.org/raw/master/tutorials/tutorial_unitary_event_analysis/data/dataset-1.nix to '/tmp/elephant/dataset-1.nix': 1.69MB [00:01, 1.11MB/s]
Calculate Unitary Events¶
[3]:
UE = ue.jointJ_window_analysis(
spiketrains, bin_size=5*pq.ms, win_size=100*pq.ms, win_step=10*pq.ms, pattern_hash=[3])
plot_ue(spiketrains, UE, significance_level=0.05)
plt.show()
/home/docs/checkouts/readthedocs.org/user_builds/elephant/conda/latest/lib/python3.12/site-packages/elephant/conversion.py:1147: UserWarning: Binning discarded 1 last spike(s) of the input spiketrain
warnings.warn("Binning discarded {} last spike(s) of the "
/home/docs/checkouts/readthedocs.org/user_builds/elephant/conda/latest/lib/python3.12/site-packages/matplotlib/_fontconfig_pattern.py:88: PyparsingDeprecationWarning: 'parseString' deprecated - use 'parse_string'
parse = parser.parseString(pattern)
/home/docs/checkouts/readthedocs.org/user_builds/elephant/conda/latest/lib/python3.12/site-packages/matplotlib/_fontconfig_pattern.py:92: PyparsingDeprecationWarning: 'resetCache' deprecated - use 'reset_cache'
parser.resetCache()
/home/docs/checkouts/readthedocs.org/user_builds/elephant/conda/latest/lib/python3.12/site-packages/matplotlib/_mathtext.py:2010: PyparsingDeprecationWarning: 'oneOf' deprecated - use 'one_of'
p.space = oneOf(self._space_widths)("space")
/home/docs/checkouts/readthedocs.org/user_builds/elephant/conda/latest/lib/python3.12/site-packages/matplotlib/_mathtext.py:2020: PyparsingDeprecationWarning: 'leaveWhitespace' deprecated - use 'leave_whitespace'
)("sym").leaveWhitespace()
/home/docs/checkouts/readthedocs.org/user_builds/elephant/conda/latest/lib/python3.12/site-packages/matplotlib/_mathtext.py:1984: PyparsingDeprecationWarning: 'setName' deprecated - use 'set_name'
val.setName(key)
/home/docs/checkouts/readthedocs.org/user_builds/elephant/conda/latest/lib/python3.12/site-packages/matplotlib/_mathtext.py:1987: PyparsingDeprecationWarning: 'setParseAction' deprecated - use 'set_parse_action'
val.setParseAction(getattr(self, key))
/home/docs/checkouts/readthedocs.org/user_builds/elephant/conda/latest/lib/python3.12/site-packages/matplotlib/_mathtext.py:2080: PyparsingDeprecationWarning: 'endQuoteChar' argument is deprecated, use 'end_quote_char'
p.text = cmd(r"\text", QuotedString('{', '\\', endQuoteChar="}"))
/home/docs/checkouts/readthedocs.org/user_builds/elephant/conda/latest/lib/python3.12/site-packages/matplotlib/_mathtext.py:2138: PyparsingDeprecationWarning: 'unquoteResults' argument is deprecated, use 'unquote_results'
p.math_string = QuotedString('$', '\\', unquoteResults=False)
/home/docs/checkouts/readthedocs.org/user_builds/elephant/conda/latest/lib/python3.12/site-packages/matplotlib/_mathtext.py:2162: PyparsingDeprecationWarning: 'parseString' deprecated - use 'parse_string'
result = self._expression.parseString(s)
/home/docs/checkouts/readthedocs.org/user_builds/elephant/conda/latest/lib/python3.12/site-packages/pyparsing/util.py:466: PyparsingDeprecationWarning: 'parseAll' argument is deprecated, use 'parse_all'
return fn(self, *args, **kwargs)
/home/docs/checkouts/readthedocs.org/user_builds/elephant/conda/latest/lib/python3.12/site-packages/matplotlib/_mathtext.py:2170: PyparsingDeprecationWarning: 'resetCache' deprecated - use 'reset_cache'
ParserElement.resetCache()