Spike train surrogates¶
Module to generate surrogates of a spike train by randomising its spike times in different ways (see [1]). Different methods destroy different features of the original data:
- randomise_spikes:
- randomly reposition all spikes inside the time interval (t_start, t_stop). Keeps spike count, generates Poisson spike trains with time-stationary firing rate
- dither_spikes:
- dither each spike time around original position by a random amount; keeps spike count and firing rates computed on a slow temporal scale; destroys ISIs, making them more exponentially distributed
- dither_spike_train:
- dither the whole input spike train (i.e. all spikes equally) by a random amount; keeps spike count, ISIs, and firing rates computed on a slow temporal scale
- jitter_spikes:
- discretise the full time interval (t_start, t_stop) into time segments and locally randomise the spike times (see randomise_spikes) inside each segment. Keeps spike count inside each segment and creates locally Poisson spike trains with locally time-stationary rates
- shuffle_isis:
- shuffle the inter-spike intervals (ISIs) of the spike train randomly, keeping the first spike time fixed and generating the others from the new sequence of ISIs. Keeps spike count and ISIs, flattens the firing rate profile
- joint_isi_dithering:
- calculate the Joint-ISI distribution and moves spike according to the probability distribution, that results from a fixed sum of ISI_before and the ISI_afterwards. For further details see [1].
References¶
- [1] Louis et al (2010). Surrogate Spike Train Generation Through Dithering in
- Operational Time. Front Comput Neurosci. 2010; 4: 127.
- [2] Gerstein, G. L. (2004). Searching for significance in spatio-temporal
- firing patterns. Acta Neurobiologiae Experimentalis, 64(2), 203-208.
Original implementation by: Emiliano Torre [e.torre@fz-juelich.de]
-
class
elephant.spike_train_surrogates.JointISI(spiketrain, dither=array(15.) * ms, truncation_limit=array(100.) * ms, num_bins=100, sigma=array(2.) * ms, alternate=True, use_sqrt=False, method='fast', cutoff=True, refr_period=array(4.) * ms)[source]¶ The class
JointISIis implemented for Joint-ISI dithering as a continuation of the ideas of Louis et al. (2010) and Gerstein (2004).When creating a class instance, all necessary preprocessing steps are done to use
JointISI.dithering()method.Parameters: - spiketrainneo.SpikeTrain
Input spiketrain to create surrogates from.
- ditherpq.Quantity, optional
This quantity describes the maximum displacement of a spike, when method is ‘window’. It is also used for the uniform dithering for the spikes, which are outside the regime in the Joint-ISI histogram, where Joint-ISI dithering is applicable. Default: 15. * pq.ms.
- truncation_limitpq.Quantity, optional
The Joint-ISI distribution of
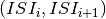 is defined
within the range [0, inf]. Since this is computationally not
feasible, the Joint-ISI distribution is truncated for high ISI.
The Joint-ISI histogram is calculated for
from 0 to truncation_limit.
Default: 100 * pq.ms.
is defined
within the range [0, inf]. Since this is computationally not
feasible, the Joint-ISI distribution is truncated for high ISI.
The Joint-ISI histogram is calculated for
from 0 to truncation_limit.
Default: 100 * pq.ms.- num_binsint, optional
The size of the joint-ISI-distribution will be num_bins*num_bins/2. Default: 100.
- sigmapq.Quantity, optional
The standard deviation of the Gaussian kernel, with which the data is convolved. Default: 2. * pq.ms.
- alternateboolean, optional
If True, then all even spikes are dithered followed by all odd spikes. Otherwise, the spikes are dithered in ascending order from the first to the last spike. Default: True.
- use_sqrtboolean, optional
If True, the joint-ISI histogram is preprocessed by applying a square root (following Gerstein et al. 2004). Default: False.
- method{‘fast’, window’}, optional
- ‘fast’: the spike can move in the whole range between the
- previous and subsequent spikes (computationally efficient).
- ‘window’: the spike movement is limited to the parameter dither
Default: ‘fast’.
- cutoffboolean, optional
If True, then the filtering of the Joint-ISI histogram is limited on the lower side by the minimal ISI. This can be necessary, if in the data there is a certain refractory period, which will be destroyed by the convolution with the 2d-Gaussian function. Default: True.
- refr_periodpq.Quantity, optional
Defines the refractory period of the dithered spiketrain unless the smallest ISI of the spiketrain is lower than this value. Default: 4. * pq.ms.
Attributes: - max_change_indexnp.ndarray or int:
For each ISI the corresponding index in the Joint-ISI distribution.
- max_change_isinp.ndarray or float:
The corresponding ISI for each index in
max_change_index.
-
dithering(self, n_surrogates=1)[source]¶ Implementation of Joint-ISI-dithering for spike trains that pass the threshold of the dense rate. If not, a uniform dithered spike train is given back. The implementation continued the ideas of Louis et al. (2010) and Gerstein (2004).
Parameters: - n_surrogates: int
The number of dithered spiketrains to be returned. Default: 1.
Returns: - dithered_sts: list of neo.SpikeTrain
Spike trains, that are dithered versions of the given
spiketrain
-
get_magnitude(self, quantity)[source]¶ Parameters: - quantity: pq.Quantity or float
Returns: - float
The magnitude of quantity, rescaled to the units of the input
spiketrain.
-
index_to_isi(self, isi_index)[source]¶ Maps isi_index back to the original ISI.
Parameters: - isi_indexnp.ndarray or int
The index of ISI.
Returns: - np.ndarray or float:
The corresponding ISI for each index.
-
isi_to_index(self, inter_spike_interval)[source]¶ A function that gives for each ISI the corresponding index in the Joint-ISI distribution.
Parameters: - inter_spike_intervalnp.ndarray or float
An array of ISIs or a single ISI.
Returns: - np.ndarray or int
The corresponding index for each ISI.
-
joint_isi_histogram(self)[source]¶ Calculates a 2D histogram of
and applies
square root or gaussian filtering if necessary.Returns: - joint_isi_histogramnp.ndarray
-
static
normalize_cumulative_distribution(array)[source]¶ This function normalizes parts of a cumulative distribution function to be a cumulative distribution function again.
Parameters: - array: np.ndarray
- A monotonously increasing array as a part of an unnormalized
cumulative distribution function.
Returns: - np.ndarray
Monotonously increasing array from 0 to 1.
-
property
too_less_spikes¶ This is a check if the
spiketrainhas enough spikes to evaluate the joint-ISI histogram.Returns: - bool
-
elephant.spike_train_surrogates.dither_spike_train(spiketrain, shift, n=1, decimals=None, edges=True)[source]¶ Generates surrogates of a spike train by spike train shifting.
The surrogates are obtained by shifting the whole spike train by a random amount of time (independent for each surrogate). Thus, ISIs and temporal correlations within the spike train are kept. For small shifts, the firing rate profile is also kept with reasonable accuracy.
The surrogates retain the spiketrain.t_start and spiketrain.t_stop. Spikes moved beyond this range are lost or moved to the range’s ends, depending on the parameter edges.
Parameters: - spiketrainneo.SpikeTrain
The spike train from which to generate the surrogates.
- shiftpq.Quantity
Amount of shift. spiketrain is shifted by a random amount uniformly drawn from the range ]-shift, +shift[.
- nint, optional
Number of surrogates to be generated. Default: 1.
- decimalsint or None, optional
Number of decimal points for every spike time in the surrogates. If None, machine precision is used. Default: None.
- edgesbool
For surrogate spikes falling outside the range [spiketrain.t_start, spiketrain.t_stop), whether to drop them out (for edges = True) or set them to the range’s closest end (for edges = False). Default: True.
Returns: - list of neo.SpikeTrain
Each surrogate spike train obtained independently from spiketrain by randomly dithering the whole spike train. The time range of the surrogate spike trains is the same as in spiketrain.
Examples
>>> import quantities as pq >>> import neo ... >>> st = neo.SpikeTrain([100, 250, 600, 800] * pq.ms, t_stop=1 * pq.s) >>> print(dither_spike_train(st, shift = 20*pq.ms)) [<SpikeTrain(array([ 96.53801903, 248.57047376, 601.48865767, 815.67209811]) * ms, [0.0 ms, 1000.0 ms])>] >>> print(dither_spike_train(st, shift = 20*pq.ms, n=2)) [<SpikeTrain(array([ 92.89084054, 242.89084054, 592.89084054, 792.89084054]) * ms, [0.0 ms, 1000.0 ms])>, <SpikeTrain(array([ 84.61079043, 234.61079043, 584.61079043, 784.61079043]) * ms, [0.0 ms, 1000.0 ms])>] >>> print(dither_spike_train(st, shift = 20 * pq.ms, decimals=0)) [<SpikeTrain(array([ 82., 232., 582., 782.]) * ms, [0.0 ms, 1000.0 ms])>]
-
elephant.spike_train_surrogates.dither_spikes(spiketrain, dither, n=1, decimals=None, edges=True)[source]¶ Generates surrogates of a spike train by spike dithering.
The surrogates are obtained by uniformly dithering times around the original position. The dithering is performed independently for each surrogate.
The surrogates retain the spiketrain.t_start and spiketrain.t_stop. Spikes moved beyond this range are lost or moved to the range’s ends, depending on the parameter edges.
Parameters: - spiketrainneo.SpikeTrain
The spike train from which to generate the surrogates.
- ditherpq.Quantity
Amount of dithering. A spike at time t is placed randomly within ]t-dither, t+dither[.
- nint, optional
Number of surrogates to be generated. Default: 1.
- decimalsint or None, optional
Number of decimal points for every spike time in the surrogates. If None, machine precision is used. Default: None.
- edgesbool, optional
For surrogate spikes falling outside the range [spiketrain.t_start, spiketrain.t_stop), whether to drop them out (for edges = True) or set them to the range’s closest end (for edges = False). Default: True.
Returns: - list of neo.SpikeTrain
Each surrogate spike train obtained independently from spiketrain by randomly dithering its spikes. The range of the surrogate spike trains is the same as of spiketrain.
Examples
>>> import quantities as pq >>> import neo ... >>> st = neo.SpikeTrain([100, 250, 600, 800] * pq.ms, t_stop=1 * pq.s) >>> print(dither_spikes(st, dither = 20 * pq.ms)) [<SpikeTrain(array([ 96.53801903, 248.57047376, 601.48865767, 815.67209811]) * ms, [0.0 ms, 1000.0 ms])>] >>> print(dither_spikes(st, dither = 20 * pq.ms, n=2)) [<SpikeTrain(array([ 104.24942044, 246.0317873 , 584.55938657, 818.84446913]) * ms, [0.0 ms, 1000.0 ms])>, <SpikeTrain(array([ 111.36693058, 235.15750163, 618.87388515, 786.1807108 ]) * ms, [0.0 ms, 1000.0 ms])>] >>> print(dither_spikes(st, dither = 20 * pq.ms, decimals=0)) [<SpikeTrain(array([ 81., 242., 595., 799.]) * ms, [0.0 ms, 1000.0 ms])>]
-
elephant.spike_train_surrogates.jitter_spikes(spiketrain, binsize, n=1)[source]¶ Generates surrogates of a spike train by spike jittering.
The surrogates are obtained by defining adjacent time bins spanning the spiketrain range, and randomly re-positioning (independently for each surrogate) each spike in the time bin it falls into.
The surrogates retain the spiketrain.t_start and spiketrain.t_stop. Note that within each time bin the surrogate spike trains are locally Poissonian (the inter-spike-intervals are exponentially distributed).
Parameters: - spiketrainneo.SpikeTrain
The spike train from which to generate the surrogates.
- binsizepq.Quantity
Size of the time bins within which to randomize the spike times. Note: the last bin lasts until spiketrain.t_stop and might have width different from binsize.
- nint, optional
Number of surrogates to be generated. Default: 1.
Returns: - list of neo.SpikeTrain
Each surrogate spike train obtained independently from spiketrain by randomly replacing its spikes within bins of user-defined width. The time range of the surrogate spike trains is the same as in spiketrain.
Examples
>>> import quantities as pq >>> import neo ... >>> st = neo.SpikeTrain([80, 150, 320, 480] * pq.ms, t_stop=1 * pq.s) >>> print(jitter_spikes(st, binsize=100 * pq.ms)) [<SpikeTrain(array([ 98.82898293, 178.45805954, 346.93993867, 461.34268507]) * ms, [0.0 ms, 1000.0 ms])>] >>> print(jitter_spikes(st, binsize=100 * pq.ms, n=2)) [<SpikeTrain(array([ 97.15720041, 199.06945744, 397.51928207, 402.40065162]) * ms, [0.0 ms, 1000.0 ms])>, <SpikeTrain(array([ 80.74513157, 173.69371317, 338.05860962, 495.48869981]) * ms, [0.0 ms, 1000.0 ms])>] >>> print(jitter_spikes(st, binsize=100 * pq.ms)) [<SpikeTrain(array([ 4.55064897e-01, 1.31927046e+02, 3.57846265e+02, 4.69370604e+02]) * ms, [0.0 ms, 1000.0 ms])>]
-
elephant.spike_train_surrogates.randomise_spikes(spiketrain, n=1, decimals=None)[source]¶ Generates surrogates of a spike train by spike time randomization.
The surrogates are obtained by keeping the spike count of the original spiketrain, but placing the spikes randomly in the interval [spiketrain.t_start, spiketrain.t_stop]. The generated independent neo.SpikeTrain objects follow Poisson statistics (exponentially distributed inter-spike intervals).
Parameters: - spiketrainneo.SpikeTrain
The spike train from which to generate the surrogates.
- nint, optional
Number of surrogates to be generated. Default: 1.
- decimalsint or None, optional
Number of decimal points for every spike time in the surrogates. If None, machine precision is used. Default: None.
Returns: - list of neo.SpikeTrain
Each surrogate spike train obtained independently from spiketrain by randomly distributing its spikes in the interval [spiketrain.t_start, spiketrain.t_stop].
Examples
>>> import quantities as pq >>> import neo ... >>> st = neo.SpikeTrain([100, 250, 600, 800] * pq.ms, t_stop=1 * pq.s) >>> print(randomise_spikes(st)) [<SpikeTrain(array([ 131.23574603, 262.05062963, 549.84371387, 940.80503832]) * ms, [0.0 ms, 1000.0 ms])>] >>> print(randomise_spikes(st, n=2)) [<SpikeTrain(array([ 84.53274955, 431.54011743, 733.09605806, 852.32426583]) * ms, [0.0 ms, 1000.0 ms])>, <SpikeTrain(array([ 197.74596726, 528.93517359, 567.44599968, 775.97843799]) * ms, [0.0 ms, 1000.0 ms])>] >>> print(randomise_spikes(st, decimals=0)) [<SpikeTrain(array([ 29., 667., 720., 774.]) * ms, [0.0 ms, 1000.0 ms])>]
-
elephant.spike_train_surrogates.shuffle_isis(spiketrain, n=1, decimals=None)[source]¶ Generates surrogates of a spike train by inter-spike-interval (ISI) shuffling.
The surrogates are obtained by randomly sorting the ISIs of the given input spiketrain. This generates independent neo.SpikeTrain object(s) with same ISI distribution and spike count as in spiketrain, while destroying temporal dependencies and firing rate profile.
Parameters: - spiketrainneo.SpikeTrain
The spike train from which to generate the surrogates.
- nint, optional
Number of surrogates to be generated. Default: 1.
- decimalsint or None, optional
Number of decimal points for every spike time in the surrogates. If None, machine precision is used. Default: None.
Returns: - list of neo.SpikeTrain
Each surrogate spike train obtained independently from spiketrain by random ISI shuffling. The time range of the surrogate spike trains is the same as in spiketrain.
Examples
>>> import quantities as pq >>> import neo ... >>> st = neo.SpikeTrain([100, 250, 600, 800] * pq.ms, t_stop=1 * pq.s) >>> print(shuffle_isis(st)) [<SpikeTrain(array([ 200., 350., 700., 800.]) * ms, [0.0 ms, 1000.0 ms])>] >>> print(shuffle_isis(st, n=2)) [<SpikeTrain(array([ 100., 300., 450., 800.]) * ms, [0.0 ms, 1000.0 ms])>, <SpikeTrain(array([ 200., 350., 700., 800.]) * ms, [0.0 ms, 1000.0 ms])>]
-
elephant.spike_train_surrogates.surrogates(spiketrain, n=1, surr_method='dither_spike_train', dt=None, decimals=None, edges=True)[source]¶ Generates surrogates of a spiketrain by a desired generation method.
This routine is a wrapper for the other surrogate generators in the module.
The surrogates retain the spiketrain.t_start and spiketrain.t_stop of the original spiketrain.
Parameters: - spiketrainneo.SpikeTrain
The spike train from which to generate the surrogates
- nint, optional
Number of surrogates to be generated. Default: 1.
- surr_methodstr, optional
The method to use to generate surrogate spike trains. Can be one of: * ‘dither_spike_train’: see surrogates.dither_spike_train [dt needed] * ‘dither_spikes’: see surrogates.dither_spikes [dt needed] * ‘jitter_spikes’: see surrogates.jitter_spikes [dt needed] * ‘randomise_spikes’: see surrogates.randomise_spikes * ‘shuffle_isis’: see surrogates.shuffle_isis * ‘joint_isi_dithering’: see surrogates.joint_isi_dithering Default: ‘dither_spike_train’.
- dtpq.Quantity, optional
For methods shifting spike times randomly around their original time (dither_spikes, dither_spike_train) or replacing them randomly within a certain window (jitter_spikes), dt represents the size of that shift / window. For other methods, dt is ignored. Default: None.
- decimalsint or None, optional
Number of decimal points for every spike time in the surrogates If None, machine precision is used. Default: None.
- edgesbool
For surrogate spikes falling outside the range [spiketrain.t_start, spiketrain.t_stop), whether to drop them out (for edges = True) or set them to the range’s closest end (for edges = False). Default: True.
Returns: - list of neo.SpikeTrain
Each surrogate spike train obtained independently from spiketrain according to chosen surrogate type. The time range of the surrogate spike trains is the same as in spiketrain.